
获取完整版报告原文请点击上方图片链接👆
这份报告将详细给大家介绍国内大语言模型的测试结果,包括通义千问、讯飞星火、文心一言相对GPT-4、GPT-3.5的表现。让我们一起深入了解《国内大语言模型测试报告》的内容和发现吧!
发现与总结
-
通义千问与GPT-4答案相似度高
-
三款国内大模型回答正确率结果: 通义千问>星火大模型>文心一言
-
国产中文模型的编程可用性相对较低,数据与符号处理能力还有所欠缺
-
国内大模型多语言处理能力较差,逻辑推理与数学能力也还有很大提升空间
测试结果
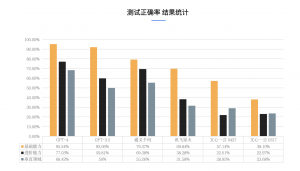
报告还揭示了一些有趣的发现。首先,通义千问在文字生成方面做得最好。至于国内模型,它们在代码能力上差别不大,但与国外模型相比仍有进步空间。不过,国内模型在API调用和语言转换方面容易出错。
另外,在事实问答中,通义千问和GPT-4表现出了很高的水平。可是,GPT-3.5、讯飞星火和文心一言在问题不合逻辑的情况下没能找出问题并给出正确答案。文心一言在情绪感知方面的失误稍微多了些,还需要改进。
进一步分析显示,GPT-4在逻辑推理、数学和物理等进阶能力方面做得最出色。通义千问在数学、语言逻辑和语义判断方面的表现已经超过了GPT-3.5,但在因果理解方面还有一些不足。讯飞星火在因果能力方面表现出色。至于垂直领域,通义千问在回答问题的准确性上与GPT-4相差不大,而文心一言和讯飞星火的正确率相对较低。
测试材料介绍
未来展望
未来,我们可以期待国内大语言模型在技术研发中的不断突破和进步。随着对大语言模型需求的不断增长,这些模型将在各个领域发挥越来越重要的作用,从而为人们带来更加智能和便捷的体验。
获取完整版报告原文请点击上方图片链接👆
DeepHow致力于应用尖端的人工智能技术建立知识技能管理平台,改变工业和制造业团队的学习和协作,专注于为企业提供技术培训和知识共享解决方案。DeepHow目前正在推出融入GPT-3.5的升级版本——DeepHow Maven,更进一步帮助企业释放劳动力潜力!
欢迎联系我们,获取产品演示:请点击链接🔗☞获取演示
以上就是本次分享的内容,感谢大家的阅读。如果对于国内大语言模型测试报告还有其他疑问或者想了解更多相关信息,欢迎留言讨论!